Creating a Simple Go Lambda Function to Save Data to S3
./john
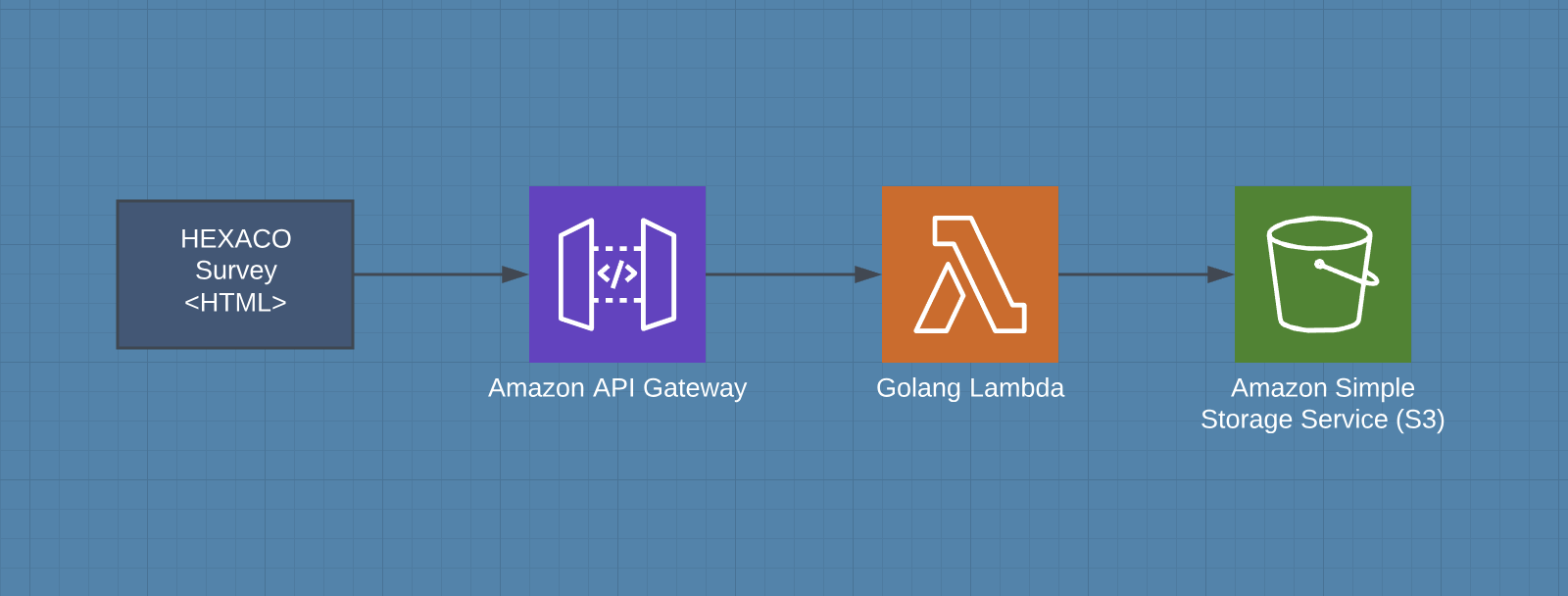
Figure 1: Basic setup for saving data to S3 with Lambda
The other day, I was writing a small proof of concept survey tool based on the HEXACO model of personality. In many cases, I would build this as a normal three-tier application:
- Presentation: HTML/CSS/JavaScript for administering the survey
- Service: Some kind of service layer and simple API
- Data/Persistence: A way to save the data
Because this was a proof of concept and I'm lazy, I decided to try to short cut this a little bit.
The first short cut is on the front end. Since the page is so simple, I implemented it as a single page application that could be served statically out of S3 or any basic file server. Because the presentation layer was so simple, no advanced application server like Node or Apache is needed.
The biggest shortcut was using lambda to write raw data to S3 rather than having a database. Normally with an application like this, I would come up with a schema in MySQL or something like that and have a Go/Docker service that takes JSON over HTTP input and writes it into the database. Rather than doing that, I created a lambda function that validates the input and writes it directly to an S3 bucket.
I probably wouldn't do something like this in many cases, but the implementation is easy to pull together and deploy. Here is the code.
The other benefit here is that I don't need to run a database just to store basic content, I can use S3 and just pay for what I'm storing.
Once the lambda function was setup and deployed, I used API Gateway to setup a public endpoint that would call this lambda function. The only tricky step here was to make sure there was some configuration for CORS. Since the front-end application is just an HTML/JS site, the calls to save data were going to be Ajax.
At this point everything worked and my data was saving successfully to S3.